



NEWS
Press release
2025.5.16
宇宙物理・宇宙論分野に特化したQUPのAIが、GPT-4oレベルのパフォーマンスを1000倍の効率で達成
小型で高度に専門化されたAIは、巨大で汎用的なAIの性能に匹敵するか、それを上回ることができるでしょうか?これが、KEKの量子場計測システム国際拠点(WPI-QUP)及び素粒子原子核研究所(IPNS)の研究者であるタイメン・デ・ハーン(Tijmen de Haan)助教と共同研究者たちが問いかけた質問です。AstroSage-8Bは、この問いに 「イエス」で答えます。新聞の見出しを飾るほとんどのAIは、数千億から数兆の数値「ウェイト」を含み、訓練と運用に莫大な費用をかけています。デ・ハーン博士はGPT-4oの100分の1以下である80億パラメータのモデルに、天文学、宇宙物理、宇宙論、宇宙科学、天体装置など、宇宙に関する領域を理解し推論することを学習させたのです。特別に訓練したAIの強力さを示す今回の結果は、2025年4月21日に『サイエンティフィック・リポーツ』誌に掲載されました。
AstroSage-8Bを作る工程は原理的には簡単ですが、実践的には大変なものでした。デ・ハーン博士が開発した手法[1]に沿った方法で、2007年以降に発表された天文学と宇宙論のほとんどすべての論文(約25万件)を集め、それらをコンピューターで読めるような形式に変換しました。デ・ハーン博士は、エクサスケール・スーパーコンピューター「フロンティア」でモデルを学習させ、宇宙関連の知識を植え付けました。そして、このモデルにチャットボットとしての動作を教え込みました。つまり、ユーザーからの問い合わせに対して、正しく、親切で明確な回答をするようにしました。1990年代のルールベースのAIシステムとは異なり、この学習は質問例を使って進めました。何百万もの合成質問と回答のペアがLLMによって生成され、別のLLMを使ってその回答の精度をチェックしました。最高品質と判断された880万組の質問と回答(Q&A)例を、天文学に特化したモデルの微調整に使いました。最後に、この学習で得られたウェイトを汎用言語モデルで平均化し、Q&Aの例ではカバーされていない機能、例えば複数往復の会話や、宇宙関連の領域外の質問に答える機能などを付与しました。
この3段階の専門的なトレーニング方法は、非常に効果的であると証明できました。4,425問の専門家ベンチマーク[2]において、AstroSage-8BはOpenAIのGPT-4oよりもわずかに高い80.9%の正答率で回答し、同時に約1,000分の1のコストで動作しました。モデルのウェイトをオープンライセンスで公開しているため、天文台、研究機関はもとより、大学や高校の教室などで、このトップクラスの天文学アシスタントをGPU1基で導入することができます。研究者は、望遠鏡での観測提案書の下書き、データ解析コードのデバッグ、知識の穴埋め、新しいアイデアの検討などに利用することができ、学生は、赤方偏移、系外惑星の大気、宇宙マイクロ波背景放射などの説明を、クイズ形式でわかりやすく得ることができます。
今回開発したAstroSage-8Bによって、明確に定義された科学分野にフォーカスした場合、コンパクトで手頃な価格のAIでも最大級の商用システムに匹敵する性能をだせるということを、実際に示すことができました。
今回の成果はさらなる希望をもたらします。AstroSage-8Bは80億(8B)のパラメータで優れたパフォーマンスを出せたわけで、今回の手法をより大きなモデルに拡張するとどうなるでしょうか? 約10倍にパラメータを増やせば、この特化した領域で最強のLLMとなるでしょうか?「答えはもうすぐわかります」とデ・ハーン博士は言っています。「私たちは次世代モデルAstroSage-70Bを現在トレーニング中で、今のところよい感じで進んでいます」。
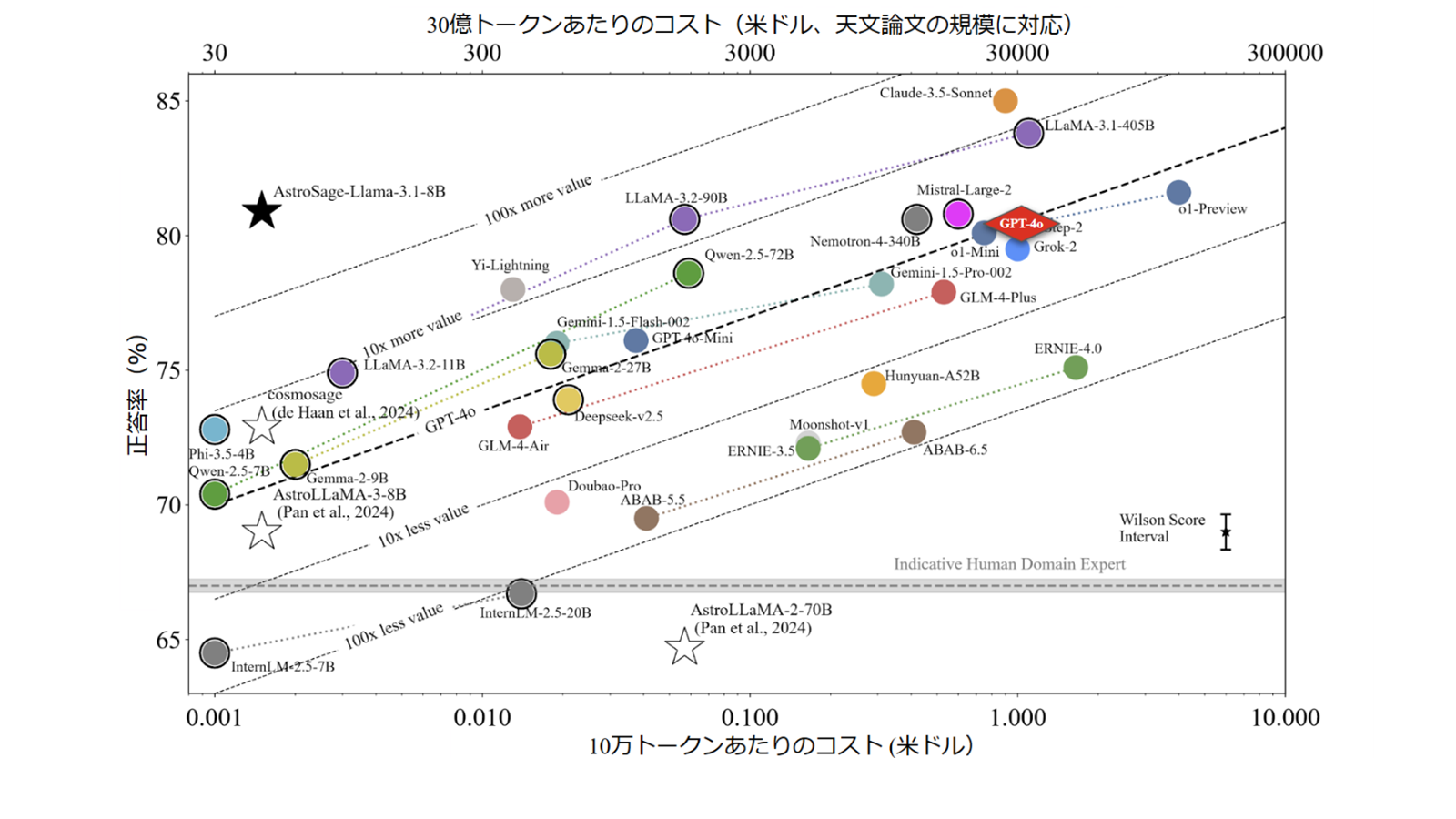
ベンチマーク性能図: 今回開発したAstroSage-8B(★)と他のAIモデルとのベンチマークテスト[2]での比較。それぞれのモデルでは、ほぼ斜めに引いた線に沿っており、性能があがればコストが高くなる。 AstroSageの性能はGPT-4o(♦)をわずかに上回る一方、約1000分の1のコストで動作しており、目的に特化したモデルが費用対効果の高いAIを生み出すことを示している。人間の専門家の正答率は灰色の横線で示している。
研究グループ
このプロジェクトはデ・ハーン博士が率い、AstroMLabとして知られる国際的なチームとの協力によります。世界中から集まったこの多様な研究者グループは、天文学者、天体物理学者、宇宙学者、自然言語処理の専門家で構成されています。
参考文献
[1] T. de Haan, “Cosmosage: A Natural‑Language Assistant for Cosmology,” Astronomy & Computing 51 (2025) 100934.
[2] Y.‑S. Ting, T. de Haan, et al., “AstroMLab 1: Who Wins Astronomy Jeopardy!?,” Astronomy & Computing 51 (2025) 100893.
掲載誌:Scientific Reports (Nature Portfolio) 15, 13751 (2025)
タイトル: AstroMLab 3: Achieving GPT-4o Level Performance in Astronomy with a Specialized 8B-Parameter Large Language Model
著者: Tijmen de Haan, Yuan-Sen Ting, Tirthankar Ghosal, Tuan Dung Nguyen, Alberto Accomazzi, Azton Wells, Nesar Ramachandra, Rui Pan, Zechang Sun
DOI: 10.1038/s41598-025-97131-y
関連リンク
高エネルギー加速器研究機構(KEK)からのプレスリリース:
https://www.kek.jp/wp-content/uploads/2025/05/pr202505161400astrosage.pdf
KEK ニュース:
https://www.kek.jp/ja/press/202505161400astrosage







